
What is Materials Informatics (MI)?
Next-generation materials development accelerated by AI × simulation
Challenges in Materials Informatics (MI) and the aim of this article
This article discusses how to overcome two key challenges in materials informatics (MI)—data scarcity and black-box behavior—by integrating simulation. It also touches on the potential of agentic generative AI and organizational aspects, and introduces ideas and example workflows to accelerate materials development.
For many years, materials development has relied heavily on trial and error based on the experience and intuition of excellent researchers. However, this traditional approach has a structural limitation: it tends to be inefficient and costly when searching for optimal candidates within a vast chemical space whose combinations are nearly infinite. As a result, the hurdle for discovering truly innovative materials remains high.
One promising approach attracting attention is Materials Informatics (MI). By using a data-driven approach, MI transforms materials exploration into a predictive and efficient process. It not only discovers new insights through large-scale data analysis, but also has the potential to accelerate the exploration process itself by working with robotic synthesis and automated experimentation.
That said, in materials domains with complex behavior, a simple data-driven approach—one that merely collects available experimental data—often struggles to deliver sufficient results. There is a growing need to partially address this challenge through integration with simulation, and to realize more effective materials design workflows grounded in physical mechanisms.
1. Challenges specific to materials design
Why are final material properties not determined by chemical composition alone? The answer lies in the hierarchical internal structure of materials, and how that structure is formed by manufacturing processes. Understanding this fundamental point is an important basis for grasping why simulation integration is necessary.
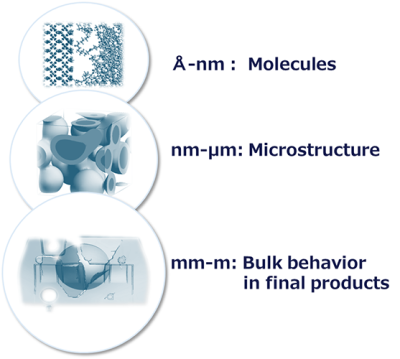
Multiscale structure
Material properties emerge across multiple length scales.
- Molecular scale (Å–nm): individual molecular structures and chemical bonds
- Mesoscale (nm–μm): morphology such as polymer chain entanglement, phase-separated structures, and interfacial structures
- Macroscale (mm–m): mechanical and thermal behavior as a bulk material
Process–Structure–Property (PSP) relationships
The internal structure of a material is dynamically determined by the manufacturing process. Steps such as mixing, curing, and deformation determine molecular orientation and aggregation states, and the resulting internal structure governs the final material properties. This chain of causality is sometimes referred to as the Process–Structure–Property (PSP) relationships. However, when one merely collects available data, it is not uncommon that only the final property values are recorded, while information on process conditions and intermediate internal structures is not sufficiently captured.

2. Challenges of data-driven Materials Informatics (MI)
The materials-specific complexity described above causes several issues, especially when applying data-driven MI approaches to the datasets available on hand.
Limited and noisy data
In many materials development cases, the absolute amount of usable data is insufficient. In addition, data are often siloed by department, and formats are not unified. If hidden variables that strongly affect properties—such as measurement conditions, lot-to-lot variation, pretreatment conditions, and process history—are not recorded, the dataset becomes incomplete and the reliability of models built on it decreases.
Insufficient features (descriptors)
In MI, it is essential to convert chemical structures and related information into numerical vectors (features or descriptors) that machines can learn from. However, simple numerical descriptors cannot adequately represent the physical entities that determine properties, such as polymer orientation, crystalline structure, entanglement, or phase-separated morphology. As a result, models may overlook key mechanisms behind property emergence.
Risk of becoming a black box
Data-driven models can fit known datasets with high accuracy. In many cases, however, they are not necessarily learning physical causality; they are capturing statistical correlations. Therefore, when trying to predict for new chemical species or different process conditions not included in the training data, reliability may drop. If the model’s rationale is unclear and it becomes a black box, MI may struggle to fulfill its original purpose: exploring unknown regions of the materials space.
3. Positioning MI and simulation integration
One solution to the limitations faced by data-driven MI is autonomous high-throughput experimentation using robots. By controlling conditions and processes, high-quality experimental data can be accumulated, and such efforts have already been reported. Another approach is integration with simulation.
Overcoming data scarcity
A straightforward approach is: when experimental data are lacking, use simulation to run virtual experiments and add data while checking accuracy and validity. This can compensate for limited experimental data and expand the dataset required to train MI models.
Obtaining physically meaningful features
A key advantage of simulation is that it can extract microscopic internal information that is difficult to measure directly in experiments, for example:
- Local 3D molecular structures and dynamics
- Interfacial structures and interaction energies
- Intermolecular forces and free volume
Reducing black-box behavior and improving explainability
Models that incorporate physical features can improve not only prediction accuracy but also physical interpretability of results. By analyzing which physical features contribute strongly to properties, one can answer the question “why does the model predict this,” and the model is expected to evolve from a mere black box into a predictive tool with explainability and credibility.
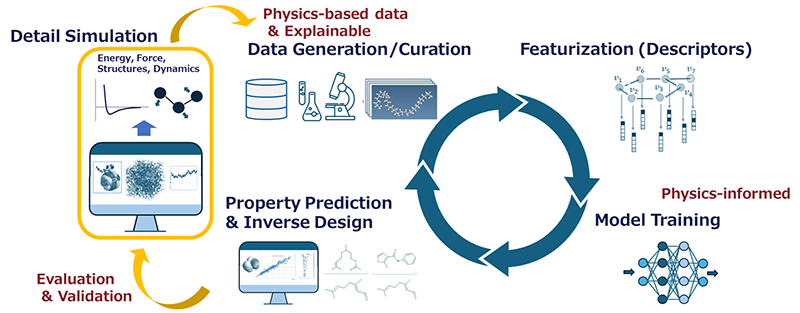
This simulation integration can be incorporated into conventional MI workflows. Compared to a linear flow of “data collection → featurization → model building,” simulation creates three intervention points.
- First, at the stage of “Data Generation/Curation,” where data are insufficient, simulation supplies various forms of data. It provides physics-based data—such as energy, force, and dynamics in microscopic regions—that cannot be obtained experimentally.
- Second, at the stage of “Property Prediction & Inverse Design,” detailed simulation analyses are performed to validate the predicted physical quantities/properties and molecular structures.
- Third (a more advanced effort), at the stage of “Model Training,” the training process is constrained by physical rules such as conservation of mass and energy, using approaches like Physics-Informed Neural Networks (PINNs), making the model “physics-informed.” Through active integration with simulation, MI is expected to move beyond statistical correlation analysis toward predictive and design tools grounded in physical mechanisms.
4.AI evolution and next-generation R&D workflows
In recent years, the role of AI has evolved significantly beyond the framework of property prediction (MI) toward supporting and automating the entire R&D process. In materials design software, the role of AI can be roughly categorized into three types.
| AI role | Description | Examples |
| Data science (MI) | Core MI technology that learns correlations between descriptors and properties using statistical models, enabling property prediction and inverse design for unknown materials. | QSPR models, clustering analysis |
| Accelerator (speed-up) | Techniques to reduce the computational cost of physical simulation and/or improve accuracy by replacing part of a physical model with a machine-learning model. | ML potentials, surrogate models |
| Agent (autonomy) | Tools that support and orchestrate research workflows. They assist researchers in dialogue form and automate parts of the process. | Script generation, modeling support, similar-structure generation, result analysis, semi-autonomous design |
A particularly important recent development is the evolution of generative AI as an “agent.” By leveraging technologies such as LLMs (large language models), efforts are being made to build “semi-autonomous design” workflows where a researcher can give a natural-language instruction like “I want a material with these properties,” and the AI proposes molecular structures, runs simulations, and even summarizes results into a report. Technical feasibility is also beginning to be discussed in various places.
In this new environment, the role of human researchers also changes. Rather than being mere operators, they will shift toward higher-level decision makers such as:
- Translating business requirements into concrete objectives for AI to optimize (properties, cost, etc.).
- Judging whether AI-generated results are physically and chemically valid, based on expert knowledge.
- Connecting acquired insights to actual product development and business strategy.
5. Embedding MI in an organization
To implement advanced technologies such as simulation-integrated MI and maximize their value, it is not enough to simply deploy powerful tools. Continuous investment and effort in people, organizational structures, and data infrastructure will be critical factors determining success.
- To use siloed, person-dependent data formats as organizational assets, it is essential to standardize rules for data collection and descriptor formats. This reduces the cost of reusing data.
- While individual property data are part of a company’s competitive domain, collaboration across companies and between industry and academia—beyond single-company optimization—in non-competitive domains such as sharing benchmark problems and unifying data formats is expected to raise the overall technical level of the industry.
- Bridge personnel who can understand across three domains—materials science (experiments and phenomenon understanding), simulation (physical modeling and numerical computation), and data science (statistics and machine learning)—and “translate” dialogue between specialists become important.
- It is necessary to shift from a passive stance of “what can we do with the data we already have” to proactive workflow design: “how do we accumulate high-quality data as part of daily operations.”
To succeed with Materials Informatics (MI)
This article organized the basic ideas of materials informatics (MI) and how simulation integration can help overcome challenges such as data scarcity and black-box behavior.
To correctly understand and control material properties, it is essential to consider hierarchical internal structures and the fact that manufacturing processes determine structures and thus properties emerge. Because of this complexity, data-driven MI faces challenges such as limited data and black-box behavior. By positioning simulation as a source of physical information and extracting physically meaningful features, it may be possible to overcome these issues and build explainable, reliable predictive models.
Integrated platforms such as J-OCTA support the adoption of these technologies by providing a foundation for individual researchers to practice them, combining state-of-the-art multiscale simulation with MI. Data accumulation, development of bridge talent, and the establishment of supporting software environments are inseparable challenges. Continued efforts on these fronts are expected to support future materials development and contribute to improved corporate competitiveness.
If you are interested in the technologies introduced here, please feel free to contact us. We also accept consultations on running MI-linked proof-of-concepts (PoCs) using J-OCTA and on building data infrastructure.
Articles in the Same Category
Related Information
Categories
New articles
- Simulation of Coating-Film Drying : A Practical Introduction to 1D/3D Analysis for Coating, Painting, and Electrode Processes
- Designing Plastic Recycling with Molecular Simulation
- What is Materials Informatics (MI)?
Next-generation materials development accelerated by AI × simulation
- Electrical conduction as a multiscale simulation
- Development of force fields used in molecular dynamics calculation
- What you need to know when using molecular modeling and simulation for materials design
- Materials & Process Informatics
- Machine Learning for Materials Design in J-OCTA - - Simulation of lithium-ion batteries
- Drug Discovery and Formulation
- Simulation of Polymeric Materials : Overview and Examples
