
マテリアルズ・インフォマティクス(MI)とは?
AI×シミュレーションで加速する次世代材料開発
マテリアルズ・インフォマティクス(MI)の課題と本記事のねらい
本記事では、マテリアルズ・インフォマティクス(MI)の課題であるデータ不足やブラックボックス化を、シミュレーション連携でどう克服するか。生成AIのエージェント化の可能性や組織論にも触れ、材料開発を加速させるための考え方とワークフロー例を紹介します。
材料の開発は、長年にわたり、優れた研究者の経験と勘に基づく試行錯誤に大きく依存してきました。しかし、この伝統的なアプローチは、組み合わせが無限に近い広大な化学空間の中から最適な候補を探索するには、非効率かつ高コストになりやすいという構造的な制約があります。結果として、真に革新的な材料を発見するハードルが高いままになっているのが現状です。
この課題を克服する有力なアプローチとして注目されているのが、マテリアルズ・インフォマティクス(MI)です。MIは、データ駆動のアプローチを用いることで、材料探索を予測的かつ効率的なプロセスへと変革します。大規模なデータ解析を通じて新たな知見を発見するだけでなく、ロボット合成や自動実験と連携することで、探索プロセスそのものを加速させる可能性を秘めています。
しかし、複雑な挙動を示す材料の領域では、手元の実験データを集めただけの単純なデータ駆動アプローチだけでは十分な成果を上げることが難しいという壁に直面します。この課題をシミュレーションとの連携によって部分的にでも解決する、物理的なメカニズムに根差した、より有効な材料設計ワークフローを実現することが求められています。
1. 材料設計に特有の課題
材料の最終的な物性は、なぜ単純な化学組成だけでは決まらないのでしょうか。その答えは、材料が持つ階層的な内部構造と、それが製造プロセスによっていかに形成されるかという点にあります。この根本的な理由を理解することは、シミュレーション連携の必要性を把握するための重要な基礎となります。
マルチスケール構造
材料はその特性が複数のスケールにまたがって発現するという特徴を持っています。
- 分子レベル(Å–nm): 個々の分子構造や化学結合
- メソスケール(nm–μm): 高分子鎖の絡み合い、相分離構造、界面構造といったモルフォロジー
- マクロスケール(mm–m): バルク材料としての機械的・熱的挙動
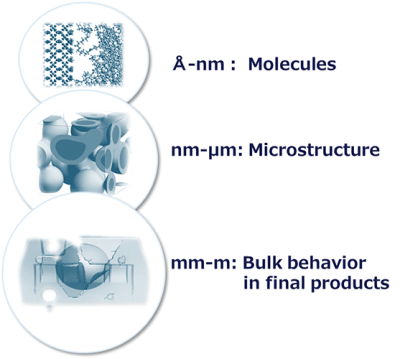
プロセス・構造・物性(Process-Structure-Property)の関係性
材料の内部構造は、製造プロセスによって動的に決定されます。混合、硬化、延伸といったプロセス工程が、分子の配向や凝集状態を決定づけ、その結果として形成された内部構造が、最終的な材料物性を支配します。この一連の因果関係は「プロセス・構造・物性(Processing-Structure-Property:PSP)」相関と言われることがあります。しかし、手元のデータを集めただけでは、最終的な物性値のみが記録され、その物性を生み出したプロセス条件や中間的な内部構造に関する情報が十分に記録されていないケースが少なくありません。

2. データ駆動型マテリアルズ・インフォマティクス(MI)の課題
前章で述べた材料特有の複雑性は、特に手元のデータセットに対してデータ駆動型MIアプローチを適用する際に、いくつかの問題を引き起こします。
限定的でノイズの多いデータ
材料開発の現場で利用可能なデータは、多くの場合、絶対量が不足しています。さらに、部門ごとにデータがサイロ化し、フォーマットが統一されていないことも珍しくありません。測定条件・ロット差・前処理条件・プロセス履歴のような、物性に大きな影響を与える隠れた変数が記録されていない場合、データセットは不完全なものとなり、これを基に構築されたモデルの信頼性は低下してしまいます。
不十分な特徴量(記述子)
MIでは、化学構造などを機械が学習可能な数値ベクトル(特徴量または記述子)に変換するプロセスが不可欠です。しかし、単純な数値記述子では、たとえば高分子の配向・結晶や絡み合いなどの三次元構造、相分離構造(モルフォロジー)といった、物性を決定づける物理的な実体を十分に表現することができません。結果として、モデルは物性発現の重要なメカニズムを見過ごすことになります。
ブラックボックス化のリスク
データ駆動モデルは、手元にある既知のデータセットに対して高い精度で適合します。しかし多くの場合、そのモデルは必ずしも物理的な因果関係を学習しているわけではなく、統計的な相関関係を捉えているに過ぎません。そのため、学習データに含まれていない新しい化学種や異なるプロセス条件に対して予測を行おうとすると、信頼性が低下する懸念があります。内部の判断根拠が不明なブラックボックスと化してしまうと、未知の材料空間を探索するというMIの本来の目的を果たしにくくなる恐れがあります。
3. マテリアルズ・インフォマティクス(MI)とシミュレーション連携の位置づけ
データ駆動型MIが直面する限界を克服するための解決策の1つは、ロボットを用いた自律型のハイスループット実験です。条件やプロセスを管理することで質の高い実験データ蓄積が可能となり、すでにそのような取り組みが報告されてきています。もう1つの手段として、シミュレーションとの連携が挙げられます。
データ不足の克服
素直なアプローチとしては、実験データが不足している場合にシミュレーションを用いて仮想的な実験を行い、精度と妥当性を確認しながらデータを追加していくことです。これにより、実験データの不足を補完し、MIモデルの学習に必要なデータセットを拡充することが可能になります。
物理的特徴量の獲得
シミュレーションの利点は、実験では直接測定することが困難な、材料内部の微視的な情報を抽出できる点にあります。
- 局所的な分子の三次元構造やダイナミクス
- 界面構造と相互作用エネルギー
- 分子間の力や自由体積
ブラックボックス化の低減と説明可能性の向上
物理的特徴量を取り入れたモデルは、予測精度を高めるだけでなく、結果に対する物理的な解釈を可能にします。どの物理的特徴量が物性に強く寄与しているかを分析することで、「なぜそのような予測結果になるのか」という問いに答えられるようになり、モデルは単なるブラックボックスではなく、説明可能性(Explainability)と納得性を備えた予測ツールへと進化させることが期待できます。
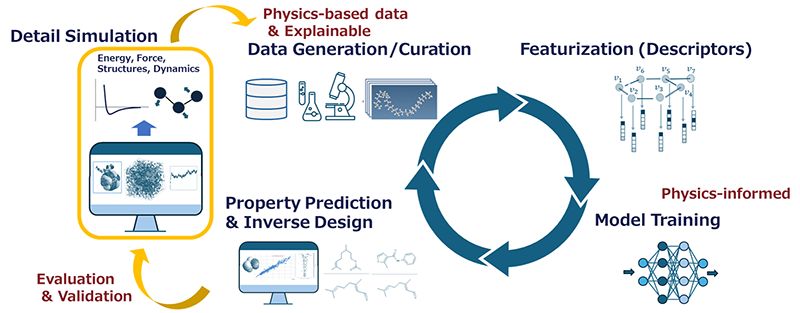
このシミュレーション連携は、従来のMIワークフローに組み込んでいくことが可能です。直線的な「データ収集 → 特徴量化 → モデル構築」というフローに対し、シミュレーションは3つの介入点を設けます。
- 第一に、データが不足する「データの生成/管理:Data Generation/Curation」の段階で、さまざまなデータを供給します。材料内部のミクロな領域のエネルギー、力、ダイナミクスといった実験では得られない物理的特徴量(Physics-based data)を提供します。
- 第二に、「物性予測と逆設計:Property Prediction & Inverse Design」の段階で、予測された物理量・物性や分子構造などの妥当性を確認するためにシミュレーションを用いた詳細解析を行います。
- 第三に、やや高度な取り組みとなりますが、「モデルの学習:Model Training」の段階で、質量やエネルギー保存則といった物理学のルールを学習プロセスに制約として与える手法(PINNsなど)を用いることで、「Physics-informed」なものにします。シミュレーションとの積極的な連携により、MIを単なる統計的な相関分析から、物理メカニズムに根差した予測・設計ツールに近づけていくことが期待できます。
4. AIの進化と次世代の研究開発ワークフロー
近年、AI技術の役割は、物性予測(MI)という枠組みだけではなく、研究開発プロセス全体を支援し、自動化する方向へと大きく進化しています。材料設計ソフトウェアにおけるAIの役割は、大きく3つに大別できます。
| AIの役割 | 説明 | 具体例 |
| データサイエンス(MI) | 統計モデルを用いて、材料の記述子と物性値の間の相関関係を学習し、未知の材料の物性予測や逆設計を行うMIの中核技術。 | QSPRモデル、クラスタリング分析 |
| アクセラレータ(高速化) | 物理シミュレーションの計算コストを削減、あるいは精度を向上させる技術。物理モデルの一部を機械学習モデルで代替する。 | 機械学習ポテンシャル、サロゲートモデル |
| エージェント(自律化) | 研究ワークフローを支援・指揮するツール。対話形式で研究者の作業を補助し、一部を自動化する。 | スクリプト生成、モデリング支援、類似構造作成、結果解析、半自律的設計 |
最近注目すべきは、「エージェント」としての生成AIの進化です。LLM(大規模言語モデル)などの技術を活用することで、研究者が「こういう特性を持つ材料が欲しい」と自然言語で指示するだけで、AIが分子構造を提案し、シミュレーションを実行、さらには結果をまとめてレポートを作成するといった「半自律的設計」ワークフローの構築に向けた取り組みが各所で試みられ、技術的な実現性も議論され始めています。
このような新しい環境下では、人間の研究者の役割も変化します。単なる計算オペレーターではなく、以下のような、より高次の意思決定者へとシフトしていくでしょう。
- ビジネス上の要求を、AIが最適化すべき具体的な目標(物性、コストなど)に変換する。
- AIが生成した結果が、物理的・化学的に妥当であるかを専門的知見に基づいて判断する。
- 得られた知見を、実際の製品開発や事業戦略に結びつける。
5. マテリアルズ・インフォマティクス(MI)を組織に根付かせるには
シミュレーション連携MIのような先進技術を導入し、その真価を最大限に発揮させるためには、強力なツールを導入するだけでは不十分です。技術を支える人、組織、データ基盤への継続的な投資・取り組みが、成功を左右する重要な要素となるでしょう。
- 部門ごとにサイロ化し、フォーマットも属人化しているデータを、組織全体の資産として活用するためには、データ収集のルールや記述子のフォーマットを標準化する取り組みが不可欠です。これにより、データを再利用するコストが低下します。
- 個別の物性データそのものは企業の競争領域ですが、ベンチマーク問題の共有やデータフォーマットの共通化といった非競争領域においては、個社最適を越えた企業間・産学間の連携が業界全体の技術水準を引き上げることが期待されます。
- 材料科学(実験・現象理解などのドメイン知識)、 シミュレーション(物理モデル化・数値計算)、 データ科学(統計・機械学習)という3つの専門領域を横断的に理解し、専門家同士の対話を「翻訳」できる橋渡し人材が重要になります。
- 「手元のデータで何ができるか」という受動的な姿勢から、「日常業務の中でいかにして質の高いデータを蓄積するか」という能動的なワークフロー設計へと転換する必要があります。
マテリアルズ・インフォマティクス(MI)を成功させるために
本記事では、マテリアルズ・インフォマティクス(MI)の基本的な考え方と、シミュレーション連携によってデータ不足やブラックボックス化の課題をどう乗り越えるかを整理しました。
材料の物性を正しく理解し制御するためには、その階層的な内部構造と、製造プロセスが構造を決定し物性が発現することの考慮が不可欠です。この複雑性ゆえに、データ駆動型MIはデータ不足やブラックボックス化といった課題に直面します。シミュレーションを物理情報の源泉と位置づけ、物理的特徴量を抽出することで、これらの課題を克服し、説明可能で信頼性の高い予測モデルを構築できる可能性があります。
統合プラットフォームJ-OCTAは、最先端のマルチスケールシミュレーション技術とMIを組み合わせることで、個々の研究者が実践するための基盤を提供し、技術の普及を支援します。データの蓄積、橋渡し人材の育成、そしてこれらを支えるソフトウェア環境の整備は、切り離すことのできない課題です。これらの課題に対する継続的な取り組みは、未来の材料開発を支え、企業の競争力向上にも寄与していくと考えられます。
ご紹介しました技術内容にご興味がございましたら、お気軽にご連絡ください。J-OCTAを用いたMI連携のPoC実施や、データ基盤構築に関するご相談も承っております。
この記事の関連情報
技術ブログカテゴリ
新着記事
- IMPETUS/VALIMATユーザー会2026を開催しました
- 接着・粘着設計とマルチスケールシミュレーション
- 医療画像3Dモデリングとは?CT・MRI(DICOMデータ)から3Dモデルを作る方法
- 微細化時代における半導体設計1:微細化と設計指針の変化
- 塗膜乾燥のシミュレーション — 塗布・塗装・電極プロセスの1D/3D解析入門
- マテリアルズ・インフォマティクス(MI)とは?
AI×シミュレーションで加速する次世代材料開発 - リアルワールドの自動車衝突安全に向けて(2)~ISOレーティング~
- 分子シミュレーションで設計するプラスチックリサイクル
- 形状設計フェーズでの組み立て精度向上によるコスト削減
~ 組み立てCE検討ツールのご紹介 ~ - JSOLが考える「溶接シミュレーションと工場デジタルツインが実現する工程設計」について講演しました
