


CAE Technical Library エンジニアレポート - CAE技術情報ライブラリ
はじめに
近年製造業においては、製品に求められる性能レベルの高まりに加え、コスト削減や開発期間の短縮などへの要求も年々厳しくなってきています。それを解決するための手段として、多数のシミュレーション結果から得られるデータを駆使した、いわゆる「データドリブンな開発」への動きも各所で見られます。
一般的なデータ活用のイメージは実験計画法などを用いて入力パラメーターと出力パラメーターの関係を推測し、入力から出力を瞬時に予測する、もしくは期待する出力を得るための入力パラメーターを類推する、といった使い方かと思います。しかし、データを数学的に処理した無機的なアウトプットだけではなく、さらに一歩進めてエンジニアの作業経緯を含むデータを記録することで可能になる、数値データだけでなく人の思考や判断などで有機的に結合されたデータにこそ、真の価値があるのではないでしょうか。
数値データと思考・判断を繋ぐためのスキームとして今回ご紹介する手法の特徴は以下の2点になります。
- ・すべての節点情報を利用し、代表的な量や指標ではなく「モード」で判断。この次元圧縮によって設計変更によって挙動に起きた変化をとらえやすく、また検索しやすくします。
- ・開発プロセスで作成されたシミュレーション結果はもちろん、その履歴情報も活用。これによってモード空間上に点在する計算結果がどの経緯をたどってきたのかを経路として可視化することができ、また検討の過程で作成されたドキュメントと紐づくことで対策の検索精度が高まります。
モード空間を用いた形状の類似度評価
まずは特徴の1つ目である、モードによる形状類似度の評価について説明します。こちらの記事で異常検知の手法としてご紹介した、モード空間上の距離で形状を比較する手法ですが、捉え方を変えると類似形状を検出することもできます。パラメトリックなキーでなく、形状そのものをキーにすることで、できることが広がります。
形状類似度の評価における数学的な背景についても先ほどの記事で紹介していますので省略しますが、複数の計算結果の対象形状を統計処理して行います。ある時刻における対象形状の節点群の座標情報から分散共分散行列を作成し固有値計算を行うことで、その時刻における形状の分布をあらわすモード空間を得ることができます。このとき、その空間上の点間距離が離れていれば形状は異なり、近ければ形状が類似しているといえます。
バージョン管理システムによる変更履歴管理
2つ目の特徴についてですが、プログラミングをされる方であればソースコードの履歴管理にGitを使用されている方もいらっしゃるのではないでしょうか。GitはもともとLinuxカーネルの開発のために開発された分散型のソースコード管理システムです。リモートリポジトリと呼ばれるデータ保管場所の情報を各開発者がローカルにクローンし、変更を加え納得のいく状態になったらリモートリポジトリに変更を登録するというのが基本的な流れになります。
構造計算で用いられる有限要素解析モデルは近年大規模化が進んでいますが、大規模になっているのは節点や形状要素・結合要素の情報がほとんどで、物性や境界条件、計算条件などはそれに比べるとデータとしてはそこまで多くありません。形状変更を含む大規模な設計空間探査のような状況でない限り、モデルの開発やモデルを使った性能開発における検討一つ一つを考えると、各バージョンのモデルに起きる差分はそこまで大きくなく、ソフトウェア開発におけるソースコード管理とそこまで大差はないとも言えます。
ここでGitをはじめとするソフトウェアコードのバージョン管理システムで重要なポイントの例をフリーのクライアントソフトであるTortoiseGitの画像を用いて挙げます。
- 1. バージョンの分岐やマージに対応している。
- 2. 変更日時や作業実施者の情報が記録される。
- 3. ファイルの変更内容に対し、人間のわかる言葉でコミットメッセージを残すことが強制される。
- 4. ソースコードの正式な更新で自動的にキックされる自動テスト機能が統合環境として機能している。
- 5. ソースコードの実行で得られるものがアーチファクトとして管理される。
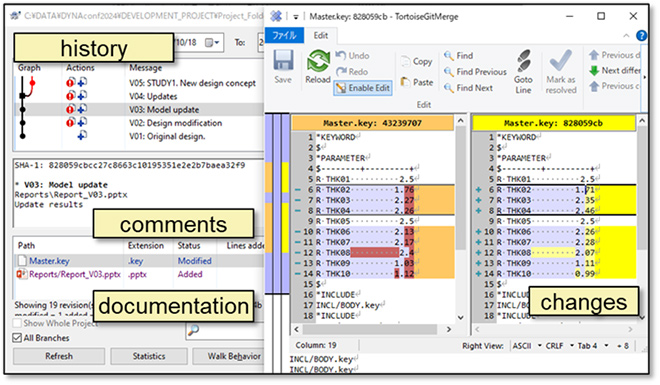
これは構造計算をはじめとするシミュレーションでモデルや性能開発を行う際にも重要となるポイントといえます。しかし、ソフトウェア開発の場合はソースコード変更において意図通りの挙動になっているかどうかが興味の中心であり、アーチファクトも作成されれば問題ありません。一方、シミュレーションでは、形状、物性、結合、境界条件などの変更により変化する計算結果それぞれにも意味があり、ポストプロセッサーで処理されたグラフやアニメーションそのものにも価値があり、それらに対して考察や議論を行った結果としてレポートや議事録といった派生的なアーチファクトが発生する点が異なっています。
現在はデータ活用というと得られた計算結果の数値データのみが着目されていますが、今後派生的なデータであるレポートや議事録を大規模言語モデル(LLM)で処理する動きが生まれると考えられています。実際にドイツでは SAFE-CAR-ML というプロジェクトで、モデルに行われた変更点を人が分かる言葉に直して変更点の自動レポート作成などに生かす活動がスタートしています。
今回は計算モデルや計算結果、そしてドキュメントを含む履歴データを活用してナレッジに昇華する考え方について紹介しました。次回は具体的な事例を用いてどのような効果が得られるかをご紹介したいと思います。