


CAE Technical Library エンジニアレポート - CAE技術情報ライブラリ
データサイエンス技術を用いた材料設計の手法としてマテリアルズ・インフォマティクス(MI)が提唱されて10年以上が経過しました。経験や勘、偶然に頼ってきた従来の材料開発に代わる画期的な手法として注目されてきたMIは、すでに研究開発の現場で定着してきていると考えられています[1]。JSOLでは、特にシミュレーションとデータサイエンスの連携に注目しており、MIのための機械学習機能をまとめた「MI-Suite」[2]というソフトウェアを提供しています。
本記事では、JSOLがMIやシミュレーションに関わる製造業の方々と接する中で、共通で挙げられる課題をご紹介します。
MIにおけるデータの流れ
図1はMIにおいて議題になるトピックや技術を、データの流れに焦点を当ててまとめたものです。大きく「データ収集・加工」、「データ蓄積」、「データ解析・最適化」の3つの「ステージ」に分割し、それぞれのステージにおける共通課題を列挙しています。
以下では、まず「データ解析・最適化」から取り上げます。続いて、「データ収集・加工」、「データ蓄積」について説明します。
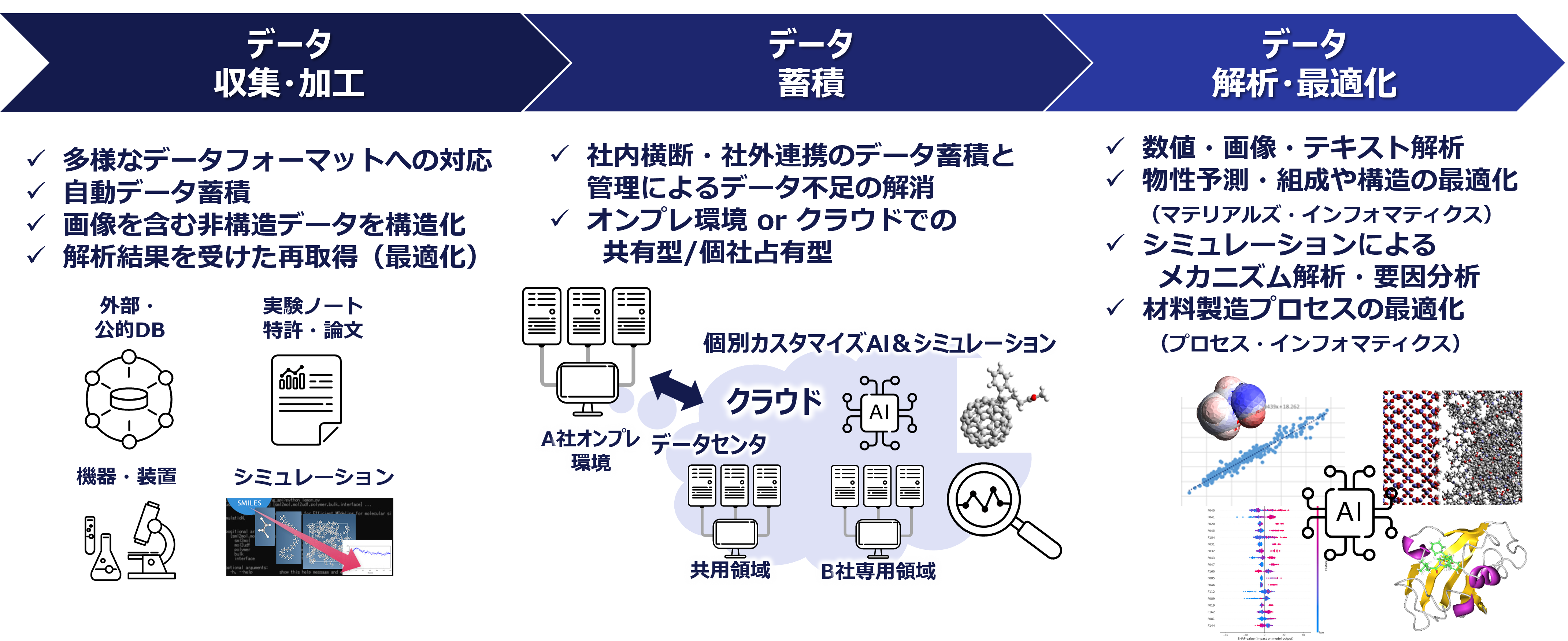 図1. マテリアルズ・インフォマティクスの3つのステージと、各ステージのトピック
図1. マテリアルズ・インフォマティクスの3つのステージと、各ステージのトピック
データ解析・最適化
「データ解析・最適化」は、データの流れからすると図1のとおり右側の最終段階に位置しますが、MIがもたらす成果に直結することから、提唱された当初から注目度が最も高かったステージです。実際に、MIと言われればこの部分をイメージする方が多いでしょう。
このステージのトピックとして、機械学習などのデータサイエンス技術を活用して得られた材料構造から物性を予測する取り組みをご紹介します。機械学習による物性予測は、物理シミュレーションよりも高速に行うことができるため、分子構造を網羅的に探索して候補材料を見つけるスクリーニングに利用できます[3,4]。また、求める物性を発現する分子構造や材料組成を見つけることが製造業では求められますので、逆問題を扱える手法があると有用です[3,5]。
MIに用いるデータに、数値、画像、テキストのほか、材料内部の情報以外にプロセスに関する情報も用いられるなど(プロセス・インフォマティクス(PI)とも呼ばれます)、常に新しい技術が登場しています。従来のシミュレーション技術との連携もなされており、たとえばデータサイエンスで大まかに予測された情報に対して、シミュレーションを用いることで詳細な解析や要因分析などを行えます。多くの企業においてこのステージから取り組みが始められていますので、身近に感じる方も多いと思います。
一方で、専門家に相談しつつPoC(Proof of Concept:概念実証)を実施したところで、取り組みが一段落してしまっている事例も多くあるようです。“何かしらの結果は得られたものの今後どのように活用するか”、の段階で停滞している状態です。さらに言えば、十分なデータ量が確保できるか、ということも課題になります。
そこで、研究開発の現場で定着してきたMIを製造業で活用するために必要となる「データ収集・加工」にも注目が集まっています(図1左側)。
データ収集・加工
MIに必要なデータ量を集めるために、さまざまなリソースを活用することになります。手元に使えるデータが少ない場合、外部の公的DBの活用が考えられますが、同じ物質の物性でも複数の異なる実験値が含まれていることや、データそのものが整えられていていないなど、データのばらつきが問題になることもあります。くわえて、公開されている汎用的な物性値では「自社材料に適用するには情報が足りない」ということもあるようです。
自社で実施した実験・測定により得られたデータを活用する場合でも、データフォーマットが問題になることがあります。最近になって実験装置の出力フォーマット統一化の動きも出ています[6]が、各研究者が自分なりのデータのまとめ方をしていることもあります。DXの取り組みとして電子実験ノートの導入を進めたものの、データを一旦サーバーに放り込んだままで、どのように運用するかは「議論中」という企業も多くあるようです。
最近では、ロボットを用いた自動実験により大量にデータを得る取り組み[7]、シミュレーションの大量実行により物性だけでなく自社にとって重要な材料内部の物理量を収集する取り組み[8-11]、データの加工に生成AI技術を用いる取り組みやアイデアなども聞きます。今後はデータサイエンスの技術以外に、データ収集・加工の部分でも技術が発展していくものと思われます。
データ蓄積
最後は、図1の中央にある「データ蓄積」です。ここで議論になるのは、セキュリティやコストです。機密性の高さやサーバー管理費を考慮して、自社内(オンプレ環境)またはクラウド環境にデータを保管します。データ保管をスムーズに立ち上げる手段としては、ビジネス系で多くの実績があるデータウェアハウス(DWH)[12]などのサービスを活用することが挙げられます。一方で、たとえば大量のシミュレーションデータをどのような形で保存するかについて深く考える必要があるでしょう。
また、自社内部門間の連携も課題になります。研究開発部門とそれ以外の部門間、さらに開発部門内でも異なるチーム間での連携など、運用の調整が難しい場合には、社内外の有識者を交えての議論になります。
さいごに
以上、MIの製造業への普及をテーマに3つのトピックを概観しました。データサイエンス技術そのものが注目されがちですが、データ量を確保するためにも周囲のシステム化も含めた取り組みが必要となっています。
JSOLは、シミュレーションとデータサイエンスの連携に強みを持ち、ITコンサルティングからシステムの構築・運用にいたるまで一貫したトータルソリューションを提供します。
本記事に記載されている内容についてご相談等がございましたら、こちらからお気軽にお問い合わせください。
- 参考文献
-
- [1] 日本ゴム協会誌, 97, pp327-332, (2024)
- [2] 機械学習を用いた物性推算機能MI-Suite
- [3] 高分子のデータ科学
- [4] 機械学習による沸点、屈折率、比誘電率の推算
- [5] mol-inferを用いたQSPRの逆解析
- [6] 計測分析装置の分析データ共通フォーマット
- [7] Nature, 624, pp86-91, (2023)
- [8] Millions of new materials discovered with deep learning
- [9] データ駆動型高分子材料研究を変革するデータ基盤創出
- [10] MD モデリング API
- [11] The Open Molecules 2025 (OMol25) Dataset, Evaluations, and Models
- [12] Snowflake
